
RAG is an AI framework that helps large language models (LLMs) like GPT-3 or GPT-4 provide more accurate and up-to-date information by retrieving facts from an external knowledge base. This technique gives users a better understanding of how LLMs generate their responses.
Large language models can sometimes give inconsistent answers. While they understand how words are related based on statistics, they don’t always understand the meaning behind them.
RAG improves the quality of LLM-generated responses by using external sources of knowledge to supplement the model’s internal information.
Implementing RAG in an LLM-based question answering system has two main benefits:
- It ensures the model has access to the most current and reliable facts.
- It allows users to check the model’s sources, making its responses more trustworthy.
This article explains RAG in more detail, with examples and applications. You can learn more about large language models by taking our course.
Why is a Retrieval Augmented Generation (RAG) implemented in LLMs? Let’s explore an example
Let’s say you work for a company that sells phones and laptops. You want to make a chatbot to help customers with questions about products. You’re thinking of using LLMs like GPT-3 or GPT-4 for this.
- Lack of specific information: LLMs provide general answers based on their training data. They may struggle to answer specific questions about your products or perform detailed troubleshooting, as they lack access to your organization’s specific data. Additionally, their training data may become outdated over time.
- Hallucinations: LLMs can generate false responses confidently, based on incorrect information. They may also provide off-topic responses if they can’t find an accurate answer, which can frustrate users.
- Generic responses: LLMs often give generic responses that don’t consider individual user needs. This can be problematic in customer support, where personalized responses are crucial.
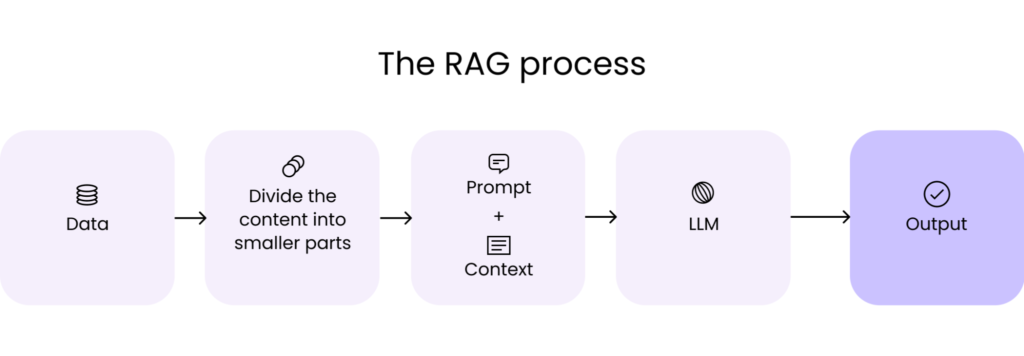
How does a Retrieval Augmented Generation (RAG) work? A step-by-step guide
Now that you understand what RAG is, let’s look at the steps involved in setting up this framework:
Step 1: Data collection
You must first gather all the data that is needed for your application. In the case of a customer support chatbot for an electronics company, this can include user manuals, a product database, and a list of FAQs.
Step 2: Data chunking
Data chunking is the process of breaking your data down into smaller, more manageable pieces. For instance, if you have a lengthy 100-page user manual, you might break it down into different sections, each potentially answering different customer questions.
This way, each chunk of data is focused on a specific topic. When a piece of information is retrieved from the source dataset, it is more likely to be directly applicable to the user’s query, since we avoid including irrelevant information from entire documents.
This also improves efficiency, since the system can quickly obtain the most relevant pieces of information instead of processing entire documents.
Step 3: Document embeddings
Now that the source data has been broken down into smaller parts, it needs to be converted into a vector representation. This involves transforming text data into embeddings, which are numeric representations that capture the semantic meaning behind text.
In simple words, document embeddings allow the system to understand user queries and match them with relevant information in the source dataset based on the meaning of the text, instead of a simple word-to-word comparison.
This method ensures that the responses are relevant and aligned with the user’s query.
If you’d like to learn more about how text data is converted into vector representations, we recommend exploring our tutorial on text embeddings with the OpenAI API.
Step 4: Handling user queries
When a user query enters the system, it must also be converted into an embedding or vector representation. The same model must be used for both the document and query embedding to ensure uniformity between the two.
Once the query is converted into an embedding, the system compares the query embedding with the document embeddings.
It identifies and retrieves chunks whose embeddings are most similar to the query embedding, using measures such as cosine similarity and Euclidean distance.
These chunks are considered to be the most relevant to the user’s query.
Step 5: Generating responses with an LLM
The retrieved text chunks, along with the initial user query, are fed into a language model. Also, the algorithm will use this information to generate a coherent response to the user’s questions through a chat interface.
Let’s Look At The Real-World Applications of RAG
Now that we understand how RAG enhances LLMs, let’s explore some practical ways this technology can be used in business to improve efficiency and user experience.
In addition to the customer chatbot example we discussed earlier, here are some other applications of RAG:
Text Summarization
RAG can be used to create concise summaries of large texts from external sources.
Moreover, this can save time for busy professionals who need to quickly understand key points from lengthy reports or articles.
Personalized Recommendations
RAG can analyze customer data, such as purchase history and preferences, to provide personalized recommendations.
For example, it can suggest products or services based on a customer’s previous interactions, improving user experience and increasing sales.
Business Intelligence
RAG can help organizations gain insights from large volumes of data, such as market trends and competitor analysis.
By analyzing external sources, RAG can provide valuable information that can inform strategic decision-making and improve overall business performance.

Implementing RAG Systems: Challenges and Best Practices
While Retrieval Augmented Generation (RAG) systems help bridge the gap between information retrieval and natural language processing, their implementation comes with unique challenges.
Let’s look into these complexities and explore ways to overcome them.
Integration Complexity
Integrating a retrieval system with a Large Language Model (LLM) can be challenging, especially with multiple sources of data in different formats.
To ensure consistency in the data fed into an RAG system and uniformity in the generated embeddings, separate modules can be designed to handle different data sources independently.
Each module can preprocess the data for uniformity, and a standardized model can be used to ensure consistent embeddings.
Scalability
As the volume of data increases, maintaining the efficiency of the RAG system becomes more challenging. Operations like generating embeddings, comparing text meanings, and retrieving data in real-time become computationally intensive and can slow down the system.
To address scalability challenges, distributing the computational load across different servers and investing in robust hardware infrastructure can help.
Caching frequently asked queries can also improve response time. Implementing vector databases can further mitigate scalability issues by handling embeddings efficiently and retrieving vectors aligned with each query.
Data Quality
The effectiveness of an RAG system heavily depends on the quality of the data it processes. Poor-quality data can lead to inaccurate responses.
Besides that, organizations should invest in diligent content curation and fine-tuning processes to enhance data quality.
In commercial applications, involving a subject matter expert to review and fill in information gaps before using the dataset in an RAG system can be beneficial.

Closing Thoughts
RAG stands out as a leading technique for maximizing the language capabilities of Large Language Models (LLMs) in conjunction with specialized databases. These systems tackle significant challenges in working with language models, offering an innovative approach in natural language processing.
However, like any technology, RAG applications have limitations, particularly their reliance on input data quality. To optimize RAG systems, human oversight is crucial.
Thoroughly curating data sources and leveraging expert knowledge are essential to ensure these solutions’ reliability.
For those interested in delving deeper into RAG and its application in building effective AI systems, our live training on building AI applications with is recommended.
FAQs
What is Retrieval Augmented Generation (RAG)?
RAG is a method that combines pre-trained large language models (LLMs) with external data sources, allowing for more detailed and accurate AI responses.
Why is RAG important for improving LLM functionality?
RAG addresses key limitations of LLMs, such as providing generic answers and generating false responses. By integrating LLMs with specific external data, RAG enables more precise and reliable responses tailored to the context.
How does RAG work, and what are the implementation steps?
RAG involves several steps, including data collection, data chunking, creating document embeddings, handling user queries, and generating responses using an LLM. This process ensures that user queries are matched with relevant information from external sources.
What are the challenges in implementing RAG systems, and how can they be overcome?
Challenges include integrating retrieval systems with LLMs, scalability issues, and maintaining data quality. Solutions include creating separate modules for different data sources, optimizing infrastructure, and ensuring data quality through curation and fine-tuning.
Can RAG be used with language models other than GPT-3 or GPT-4?
Yes, RAG can be used with various language models, as long as they can understand and generate language effectively. The effectiveness of RAG may vary based on the specific strengths of the language model.