TL;DR
If you’re reading this, you’ve probably heard of large language models (LLMs) like ChatGPT, Google Bard, and DALL-E. These tools are a big part of the AI revolution, but how do they actually work?
In simple terms, LLMs use advanced technology to understand questions and generate accurate answers. This article is here to help you understand LLMs better. We’ll cover what they are, how they work, the different types, and their pros and cons.
Let’s explore the details!
What is a Large Language Model (LLM)?
A Large Language Model (LLM) is a type of AI system that processes human language.
They’re called “large” because they’re made up of hundreds of millions or even billions of parameters that define how the model behaves. These parameters are pre-trained using a huge amount of text data.
The technology behind LLMs is called a transformer neural network, or just a transformer. Transformers are a type of neural architecture in deep learning that was introduced by Google researchers in 2017.
Besides that, they’re able to handle natural language tasks with incredible accuracy and speed, which has been a game-changer for LLMs.
In fact, the current AI revolution wouldn’t be possible without transformers.
After the development of transformers, the first modern Large Language Models (LLMs) emerged. Among these, BERT was the pioneer, created by Google to showcase the potential of transformers.
Additionally, OpenAI developed GPT-1 and GPT-2, which were the initial models in the GPT series.
However, it wasn’t until the 2020s that LLMs gained mainstream attention. They started to grow significantly in size (in terms of parameters), becoming more powerful. Notable examples from this era include GPT-4 and LLaMa.
What are Large Language Models (LLMs) used for?
Modern Large Language Models (LLMs), powered by transformers, have achieved state-of-the-art performance in various Natural Language Processing (NLP) tasks.
Here are some examples:
- Text generation: LLMs like ChatGPT can create long, complex, and human-like text quickly.
- Translation: Multilingual LLMs can perform high-quality translation tasks. For instance, Meta’s SeamlessM4T model can handle speech-to-text, speech-to-speech, text-to-speech, and text-to-text translations for up to 100 languages.
- Sentiment analysis: LLMs are effective in analyzing sentiment in text, such as predicting positive or negative movie reviews or opinions in marketing campaigns.
- Conversational AI: LLMs form the backbone of modern chatbots, enabling them to answer questions and hold conversations, even in complex scenarios.
- Autocomplete: LLMs can be used to suggest completions in emails or messaging apps. For example, Google’s BERT is used in Gmail’s autocomplete feature.
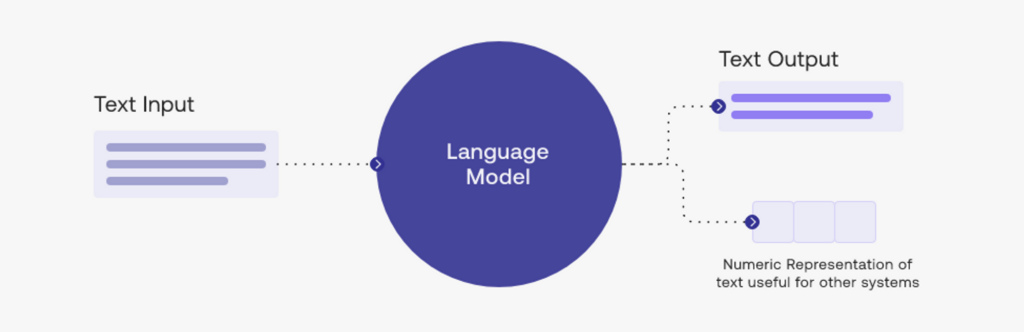
How do the Large Language Models (LLMs) work?
Modern Large Language Models (LLMs) rely on the transformer architecture, which revolutionized natural language processing.
Before transformers, using neural networks like recurrent or convolutional neural networks for language tasks had limitations.
One major challenge was predicting missing words in a sentence. Traditional neural networks used an encoder-decoder architecture, which was powerful but not efficient for parallel computing, limiting scalability.
Transformers changed this by introducing a new way to handle sequential data, especially text. Moreover, they’ve been successful not just with text but also with other data types like images and audio.
What are the components of LLMs?
Transformers are built on the same basic architecture as recurrent and convolutional neural networks, aiming to understand relationships between words in text.
This is achieved through embeddings, which are representations of words, sentences, or paragraphs in a high-dimensional space, where each dimension represents a feature or attribute of the language.
Embeddings are created in the encoder. Despite the large size of LLMs, the embedding process is highly parallelizable, making it more efficient. This is thanks to the attention mechanism.
Unlike earlier networks, which predict words based only on previous words, transformers can predict words bidirectionally, considering both preceding and following words.
Additionally, the attention mechanism, present in both the encoder and decoder, helps capture these contextual relationships.
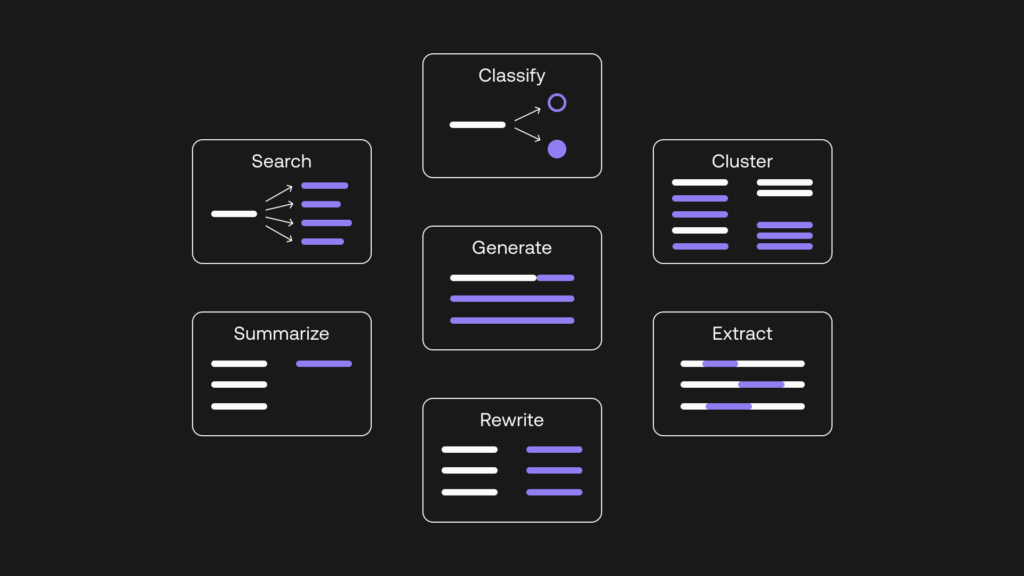
What are the types and examples of Large Language Models (LLMs)?
LLMs are highly adaptable and flexible models, leading to different types of LLMs:
- Zero-shot LLMs: These models can perform tasks without prior training examples. For example, an LLM could understand new slang based on its position and meaning within a sentence.
- Fine-tuned LLMs: Developers often fine-tune pre-trained LLMs with new data for specific purposes.
- Domain-specific LLMs: These models are tailored to understand the language and nuances of a particular field, such as healthcare or legal. Curated training data is crucial for these models to meet industry standards.
As the number of proprietary and open-source LLMs grows, it’s important to note that applications like ChatGPT are built on top of LLMs. ChatGPT, for example, is powered by GPT-3.5, while ChatGPT-Plus uses GPT-4, currently the most powerful LLM.
Popular LLMs include:
- BERT: Released by Google in 2018, BERT is one of the first and most successful modern LLMs.
- PaLM 2: An advanced LLM that powers Google Bard, a chatbot competing with ChatGPT.
- LLaMa 2: Developed by Meta, LLaMa 2 is a powerful open-source LLM.

How are LLMs Trained?
Training transformers involves two steps: pretraining and fine-tuning.
Pre-training
Pre-training is the initial phase where transformers are trained on large amounts of raw text data, primarily sourced from the internet. This training uses unsupervised learning, which doesn’t require human-labeled data.
The goal of pre-training is to learn the statistical patterns of language. To improve accuracy, modern transformers are made larger (with more parameters) and trained on bigger datasets.
For example, PaLM 2 has 340 billion parameters, and GPT-4 is estimated to have around 1.8 trillion parameters.
However, this trend poses accessibility challenges. The size of the model and the training data make pre-training time-consuming and costly, affordable only to a few companies.
Fine-tuning
Fine-tuning is the next phase, where pre-trained transformers are further trained on specific tasks to improve their performance.
Interestingly, this step separates the initial training phase from the task-specific tuning phase, allowing developers to adapt models to different tasks efficiently. Human feedback is often used in this phase, known as Reinforcement Learning from Human Feedback.
This two-step training process enables LLMs to be adapted to a wide range of tasks, making them a foundation for various applications.
Multimodality of LLMs
Initially, Large Language Models (LLMs) were designed as text-to-text models, meaning they processed text input and generated text output.
However, developers have recently created multimodal LLMs, which can process and generate output from a variety of data types, including images, audio, and video.
These multimodal models have led to the development of sophisticated, task-specific models like OpenAI’s DALL-E for image generation and Meta’s AudioCraft for music and audio generation.
Moreover, the ability to combine different types of data has opened up new possibilities for AI applications, enabling more creative and versatile outputs.

What are the advantages of LLMs?
LLMs offer several advantages for organizations, making them valuable tools in various industries:
- Content creation: LLMs are powerful gen and audio. They can generate accurate, domain-specific content for sectors like legal, finance, healthcare, and marketing.
- Enhanced performance in NLP tasks: LLMs excel in various NLP tasks, demonstrating high accuracy in understanding human language and interacting with users. However, they are not perfect and can produce inaccurate results or hallucinations.
- Increased efficiency: LLMs can complete monotonous and time-consuming tasks quickly, improving efficiency. This can benefit companies lookingerative AI tools that can create content, including text, images, videos, to streamline operations. However, it also raises considerations about the impact on workers and the job market.

What are the disadvantages of LLMs?
While Large Language Models (LLMs) offer significant benefits, they also present challenges and limitations that need to be addressed:
- Lack of transparency: LLMs are complex “black box” models, making it difficult to understand their reasoning and inner workings. AI providers often do not disclose detailed information about their models, hindering monitoring and accountability.
- LLM monopoly: Developing and operating LLMs requires substantial resources, leading to market concentration among a few big tech companies. However, the emergence of open-source LLMs is helping democratize access to these technologies.
- Bias and discrimination: LLMs can amplify biases present in training data, leading to unfair decisions that discriminate against certain groups. Transparency is crucial for identifying and mitigating biases.
- Privacy issues: LLMs are trained on vast amounts of data, including personal information extracted from the internet, raising concerns about data privacy and security.
- Ethical considerations: LLMs can make decisions with significant ethical implications, impacting fundamental rights. It’s important to consider ethical implications in the development and deployment of LLMs.
- Environmental impact: Training and operating LLMs consume substantial energy and resources, contributing to environmental concerns. However, many proprietary LLMs do not disclose their energy consumption or environmental footprint.

Concluding remarks
In conclusion, Large Language Models (LLMs) are at the forefront of the current generative AI boom, offering immense potential across various sectors and industries, including data science. Their adoption is expected to have far-reaching effects in the future.
While the possibilities with LLMs seem endless, there are also significant risks and challenges to consider.
Their transformative capabilities have sparked discussions about how AI will impact the job market and other aspects of society. This debate is crucial and requires a collective effort to address, given the high stakes involved.
As we continue to explore the capabilities of LLMs, it’s important to approach their development and use responsibly and ethically. Maximizing the benefits of LLMs while mitigating potential risks is essential for ensuring a positive impact on society.
FAQs
What are LLMs and how do they work?
A Large Language Model (LLM) is an AI program capable of recognizing and generating text, among other tasks. What sets LLMs apart is their ability to handle vast amounts of data, which is crucial for their performance. They’re built on a type of neural network called a transformer model, which is a key component of their machine learning architecture.
What is ChatGPT based on?
ChatGPT’s underlying technology is the GPT large language model (LLM), which is an algorithm that processes natural language inputs and predicts the next word based on its context. It continues this process to generate a complete answer or response.
What distinguishes LLMs from AI?
When comparing Generative AI with LLMs, the key difference lies in the type of content they can produce. Generative AI has the ability to generate a wide range of content, including images, music, code, and more, while LLMs are primarily focused on text-based tasks such as natural language understanding, text generation, language translation, and textual analysis.